爬取csdn文章
前几篇文章介绍了scrapy相关的知识. 这篇文章来介绍一个我自己写的爬虫demo. 通过关键词查询爬取相关的csdn文章.
项目介绍
爬虫类CsdnArticleRelatedSpider
CsdnArticleRelatedSpider继承CrawlSpider, 通过定义规则rules属性从页面提取链接.
这里我们定义了从获取文章详情页的链接提取规则:
rules = (
Rule(LinkExtractor('.*/article/details/.*'), callback='parse_item', follow=True),
)
文章详情页的字段提取方法可以通过callback属性进行指定, 字段的提取使用xpath实现:
def parse_item(self, response):
logger.info('[CsdnArticleSpider details] start to deal [{}]'.format(response.url))
item_loader = ItemLoader(item=CsdnArticleItem(), response=response)
item_loader.add_value('url', response.url)
item_loader.add_xpath('title', '//*[@id="articleContentId"]/text()')
item_loader.add_xpath('author', '//div[@class="bar-content"]/a[@class="follow-nickName "]/text()')
item_loader.add_xpath('post_time', '//div[@class="bar-content"]/span[@class="time"]/text()')
item_loader.add_xpath('type_label', '//div[@class="tags-box artic-tag-box"]'
'/a[contains(@href, "category")]/text()')
item_loader.add_xpath('type_label_url', '//div[@class="tags-box artic-tag-box"]'
'/a[contains(@href, "category")]/@href')
item_loader.add_xpath('article_label', '//div[@class="tags-box artic-tag-box"]'
'/a[contains(@href, "tags")]/text()')
item_loader.add_xpath('article_label_url', '//div[@class="tags-box artic-tag-box"]'
'/a[contains(@href, "tags")]/@href')
item_loader.add_xpath('view_cnt', '//span[@class="read-count"]/text()')
item_loader.add_xpath('like_cnt', '//span[@id="spanCount"]/text()')
item_loader.add_xpath('collect_cnt', '//span[@id="get-collection"]/text()')
item_loader.add_xpath('comment_cnt', '//a[@href="#commentBox"]/span[@class="count"]/text()')
item_loader.add_xpath('content_html', '//div[@id="content_views"]')
item = item_loader.load_item()
set_default(item, "type_label")
set_default(item, "article_label")
set_default(item, "author")
return item
文章信息类CsdnArticleItem
CsdnArticleItem类是我们封装的文章信息类.
class CsdnArticleItem(scrapy.Item):
"""
csdn文章
"""
title = scrapy.Field(output_processor=TakeFirst())
author = scrapy.Field(output_processor=TakeFirst())
post_time = scrapy.Field(output_processor=TakeFirst())
type_label = scrapy.Field(input_processor=MapCompose(remove_blank),
output_processor=Join(","))
type_label_url = scrapy.Field(output_processor=Join(",\n"))
article_label = scrapy.Field(input_processor=MapCompose(remove_blank),
output_processor=Join(","))
article_label_url = scrapy.Field(output_processor=Join(",\n"))
view_cnt = scrapy.Field(input_processor=MapCompose(remove_blank, set_zero),
output_processor=TakeFirst())
like_cnt = scrapy.Field(input_processor=MapCompose(remove_blank, set_zero),
output_processor=TakeFirst())
collect_cnt = scrapy.Field(input_processor=MapCompose(remove_blank, set_zero),
output_processor=TakeFirst())
comment_cnt = scrapy.Field(input_processor=MapCompose(remove_blank, set_zero),
output_processor=TakeFirst())
url = scrapy.Field(input_processor=MapCompose(remove_blank),
output_processor=TakeFirst())
file_path = scrapy.Field(input_processor=MapCompose(remove_blank))
content_html = scrapy.Field(input_processor=MapCompose(remove_blank),
output_processor=TakeFirst())
input_processor和output_processor方法是对字段进行前置和后置处理的属性.
之后通过爬虫类中的ItemLoader的load_item方法可以创建CsdnArticleItem的实例.
但是这里有一个问题, 如果爬虫类通过xpath无法获取到字段值, 那么这个字段是不存在的.
因此在上一节中load_item方法调用之后, 我们又通过set_default方法指定默认的参数.
其方法定义为:
def set_default(item, key):
try:
if item[key] is None:
item[key] = "unknown"
except KeyError:
item[key] = "unknown"
管道的使用
上面的item创建之后会传递到管道中去. 按照settings.py文件中指定的顺序对item进行处理. 这里我们使用了三个管道.
ITEM_PIPELINES = {
'article.pipelines.PrePipeline.DuplicatePipeline': 1,
'article.pipelines.PostExportPipeline.MarkdownPipeline': 5,
'article.pipelines.PostExportPipeline.CsvPipeline': 10,
}
DuplicatePipeline
该管道用于去重. 如果之前已经爬取过当前文章则不会继续往下面的管道继续传输.
该类的实现见下:
class DuplicatePipeline(object):
"""
去重 读取之前导出记录的url放到集合中, 每次获取到新的链接之后判断是否存在
如果之前存在则不进行处理
"""
def __init__(self):
self.urls = []
csv_path = config["record_path"]
if os.path.exists(csv_path):
try:
data = pd.read_csv(csv_path)
logger.debug('获取到的数据为: {}'.format(data))
self.urls = data['url'].drop_duplicates().values.tolist()
except EmptyDataError:
logger.debug('文件内容为空')
def process_item(self, item, spider):
if item['url'] in self.urls:
raise DropItem("Duplicate item found: title: [%s] url: [%s]" % (item["title"], item["url"]))
else:
self.urls.append(item['url'])
return item
初始化方法中, 加载历史的url. 这些url记录在record_path所指定的文件中.
process_item方法是进行去重实现的. 如果url已经存在直接抛出DropItem异常即可.
如果不存在我们将url加入到urls集合中去.
MarkdownPipeline
该管道用于将markdown文件进行导出
class MarkdownPipeline(object):
def __init__(self):
pass
def process_item(self, item, spider):
self.save_markdown(item)
return item
def save_markdown(self, item):
"""
保存文章内容为md格式
"""
title = item['title']
author = item['author']
label = item['article_label']
# 需要对字符串进行格式化处理
author = remove_strange_char(author)
title = remove_strange_char(title)
label = remove_strange_char(label).lower()
# 按照文章分类/作者层级创建目录并保存
dir_article = os.path.join(config['target_path'], label, author)
if not os.path.exists(dir_article):
os.makedirs(dir_article)
file_path = os.path.join(config['target_path'], label, author, title + '.md')
if not os.path.exists(file_path):
item['file_path'] = file_path
content_html = item['content_html']
if content_html:
content_md = ht.HTML2Text().handle(content_html)
with open(file_path, encoding='UTF-8', mode='w+') as md_file:
md_file.write(content_md)
将html转换为md格式我们使用了html2text第三方依赖. 这里可以定制化自己的输出路径.
CsvPipeline
该管道用于记录爬取历史. 这里我们使用CsdnArticleItemExporter进行cvs的导出. 该类继承自CsvItemExporter, 我们只需要在初始化方法中提供一些属性值即可, 最后调用父类的初始化方法.
class CsvPipeline(object):
"""
将item存为xlsx
"""
def __init__(self):
self.files = {}
self.exporter = None
def open_spider(self, spider):
file = open(config['record_path'], 'w+b')
self.files[spider] = file
self.exporter = CsdnArticleItemExporter(file)
self.exporter.start_exporting()
def close_spider(self, spider):
self.exporter.finish_exporting()
file = self.files.pop(spider)
file.close()
def process_item(self, item, spider):
if item:
self.exporter.export_item(item)
return item
class CsdnArticleItemExporter(CsvItemExporter):
"""
文章记录的导出格式设置, 按照FIELDS_TO_EXPORT中指定的顺序导出各个字段
"""
def __init__(self, *args, **kwargs):
delimiter = config['csv_delimiter']
kwargs['delimiter'] = delimiter
fields_to_export = config['fields_to_export']
if fields_to_export:
kwargs['fields_to_export'] = fields_to_export
super(CsdnArticleItemExporter, self).__init__(*args, **kwargs)
如何配置
这里需要提及3个配置文件.
scrapy.cfg 这个是scrapy框架的配置文件, 这里我们指定了settings文件名. 因此settings.py文件中的属性都会加载到settings属性中去.
[settings] default = article.csdn_article_settings ;default = src.csdn_query_settings [deploy] project = csdn_spidercsdn_article_settings.py 该文件用于设置爬虫运行所需要的环境配置. 所有的配置项可以参考settings配置
config.json 这个文件是我们自定义的配置项, 用于独立于该框架进行配置. 在main类中我们对读取其中的配置, 将其加载到全局变量中去.
{ "name": "csdn_article", "query_url": "https://so.csdn.net/api/v3/search?q=", "query": "java 反射", "start_urls": [ ], "record_path": "D:\\data\\article\\record.csv", "target_path": "D:\\data\\article\\" }比如这里我们配置了初始化时的url, 已经文件的导出路径.
如何运行
直接运行main.py, 注意需要添加--config=D:\XXXXX\config.json该文件即你的json配置文件路径.
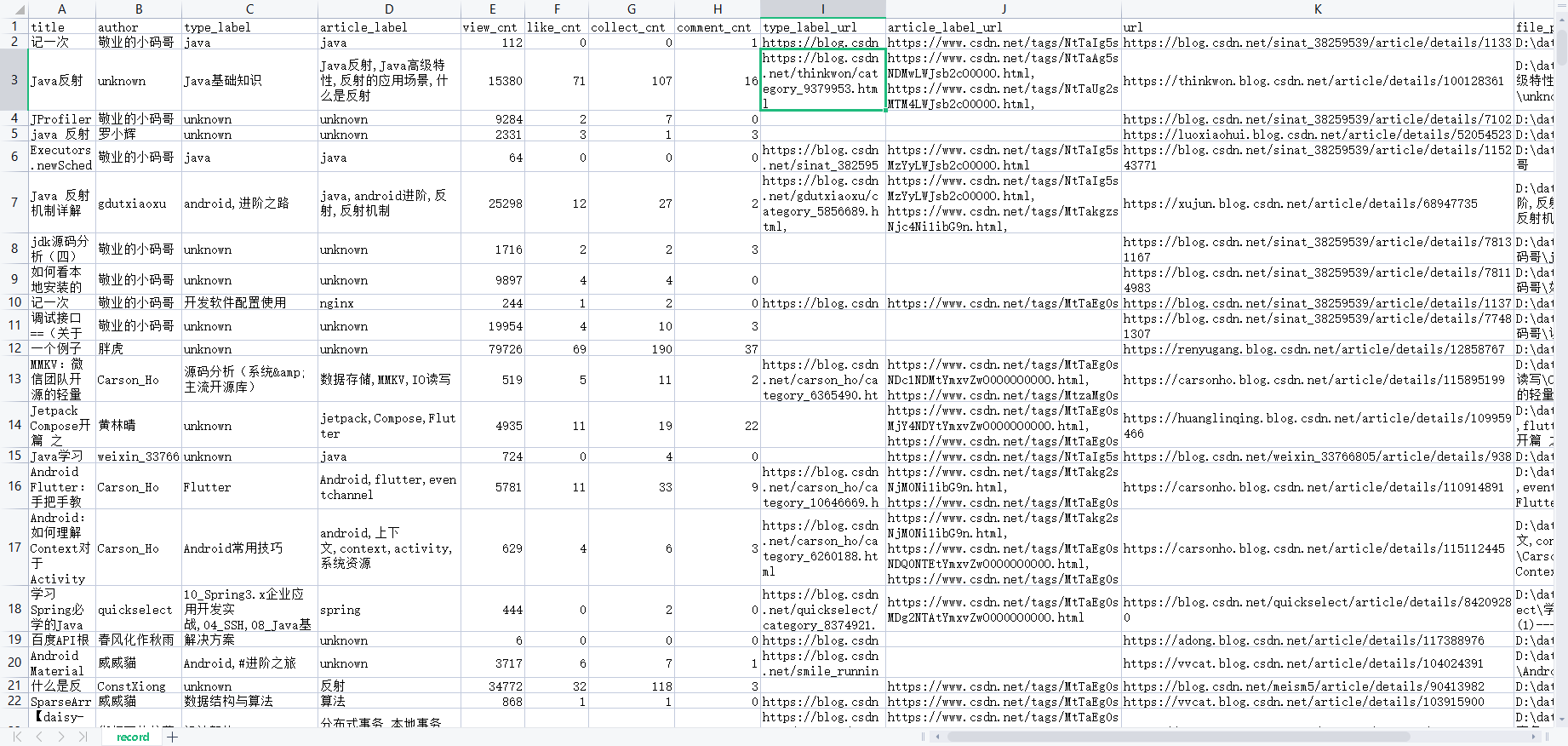
csv中的爬取记录:
爬取的文件:
爬取文件路径: