
迭代器模式
1/22/24About 6 min
迭代器模式,为集合中的有序访问提供了一致的方法,它让对象可以遍历另一个对象的数据集。这种模式可以帮助我们遍历数组、集合和哈希表等。
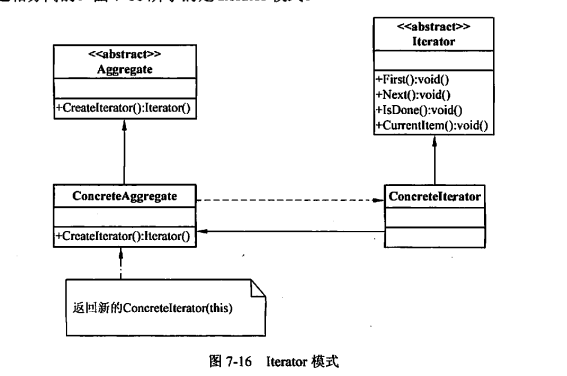
迭代器模式主要包含以下几个角色:
- Iterator(迭代器)接口: 定义了访问和遍历元素的接口。
- ConcreteIterator(具体迭代器)类: 实现了
Iterator接口,完成对聚合对象的遍历。 - Aggregate(聚合)接口: 定义创建相应迭代器对象的接口。
- ConcreteAggregate(具体聚合)类: 实现了
Aggregate接口,返回一个具体迭代器的实例。
Iterator和Aggregate是迭代器模式的核心。Iterator定义了迭代器的基本接口,Aggregate负责创建迭代器对象。
迭代器模式将迭代器的功能从聚合对象中分离出来,这样我们就可以通过迭代器来遍历不同的聚合结构,而不需要了解它们的内部实现。这使得代码更加灵活和可复用。
代码实现
迭代器接口
这里定义迭代器的抽象行为,next方法用于查找下一个元素,hasNext用于判断是否含有下一元素。这里可以参考jdk中的接口定义。
public interface Iterator<T> {
boolean hasNext();
T next();
}迭代器实现
迭代器的具体实现中实现Iterator中的抽象行为。Aggregate是聚合类,index是当前迭代器指向的元素索引。
public class ConcreteIterator<T> implements Iterator<T> {
private final Aggregate<T> aggregate;
private int index = 0;
public ConcreteIterator(Aggregate<T> aggregate) {
this.aggregate = aggregate;
}
@Override
public boolean hasNext() {
return aggregate.size() > index;
}
@Override
public T next() {
return aggregate.get(index++);
}
}聚合接口
Aggregate类是抽象聚合类,它定义创建迭代器对象的抽象方法。
public abstract class Aggregate<T> {
public abstract Iterator<T> createIterator();
public abstract void add(T info);
public abstract int size();
public abstract T get(int index);
}聚合实现
ConcreteAggregate是聚合类,它负责创建迭代器对象。
public class ConcreteAggregate<T> extends Aggregate<T> {
private final List<T> infos = new ArrayList<>();
@Override
public Iterator<T> createIterator() {
return new ConcreteIterator<>(this);
}
@Override
public void add(T info) {
this.infos.add(info);
}
@Override
public int size() {
return this.infos.size();
}
@Override
public T get(int index) {
return this.infos.get(index);
}
}测试
上面的类中我们使用了泛型,这样我们就可以扩展这个模式的使用范围,如下:
public class Client {
public static void main(String[] args) {
Aggregate<Info> aggregate = new ConcreteAggregate<>();
aggregate.add(new Info("info1"));
aggregate.add(new Info("info2"));
aggregate.add(new Info("info3"));
Iterator<Info> iterator = aggregate.createIterator();
while (iterator.hasNext()) {
Info next = iterator.next();
System.out.println(next.name);
}
Aggregate<String> aggregate2 = new ConcreteAggregate<>();
aggregate2.add("string1");
aggregate2.add("string2");
aggregate2.add("string3");
Iterator<String> iterator2 = aggregate2.createIterator();
while (iterator2.hasNext()) {
String next = iterator2.next();
System.out.println(next);
}
}
}结果:

为什么要使用迭代器模式
- 封装性:通过迭代器,集合类可以隐藏其内部数据结构的细节。客户端无需了解集合是数组、链表还是其他复杂的数据结构,只需要与迭代器接口交互即可。
- 一致性:无论集合的具体实现如何变化,只要它提供了迭代器,客户端代码就可以保持不变地遍历集合元素。这意味着你可以用同一种方式遍历任何实现了迭代器接口的对象。
- 灵活性:迭代器可以支持多种遍历操作,如正向遍历、反向遍历、有条件遍历等,而不需要修改集合类本身。另外,还可以轻松添加新的遍历功能,只需创建一个新的迭代器子类。
- 分离职责:迭代器模式将“如何遍历”与“集合是什么”这两项职责分离开来,使得集合类专注于存储和管理元素,而迭代器专注于访问这些元素的方式。
- 支持更多遍历算法:在某些情况下,可能需要对集合进行特定类型的遍历,例如过滤、映射等操作。通过定义不同的迭代器,可以支持各种复杂的遍历算法。
- 可复用性:迭代器作为一个独立的组件,可以在多个容器类中复用,从而减少代码重复并提高软件质量。
因此,迭代器模式增强了代码的抽象性和可维护性,同时简化了集合类的设计,并为用户提供了一致且灵活的遍历机制。
与其他设计模式的对比
| 设计模式 | 主要功能 | 实现方式 | 适用场景 |
|---|---|---|---|
| 迭代器模式 | 顺序访问集合元素 | 接口 + 实现 | 需要统一遍历不同集合时 |
| 访问者模式 | 元素操作分离 | 双重分发 | 需要为集合元素添加新操作时 |
| 策略模式 | 算法替换 | 组合 | 算法需要频繁切换时 |
| 命令模式 | 请求封装 | 组合 | 需要记录、撤销操作时 |
总结
核心思想
迭代器模式提供一种统一的方式来顺序访问聚合对象中的元素,而无需暴露其底层表示。它将遍历操作与集合本身分离,使得同一遍历算法可以应用于不同的集合结构。
主要角色
- 迭代器(Iterator):定义访问和遍历元素的接口
- 具体迭代器(ConcreteIterator):实现迭代器接口,完成对聚合对象的遍历
- 聚合(Aggregate):定义创建相应迭代器对象的接口
- 具体聚合(ConcreteAggregate):实现聚合接口,返回具体迭代器实例
实现方式
- 使用接口定义迭代器和聚合的抽象行为
- 具体迭代器持有聚合对象的引用,实现遍历逻辑
- 支持泛型以提高代码复用性
优点
- 封装性:隐藏集合内部数据结构的细节
- 一致性:统一遍历不同集合的方式
- 灵活性:支持多种遍历操作,如正向、反向遍历
- 分离职责:将遍历逻辑与集合管理逻辑分离
- 可复用性:迭代器可以在多个容器类中复用
缺点
- 增加类的数量:每个集合需要对应一个迭代器类,可能导致类的数量增加
- 遍历性能:相比直接访问集合元素,迭代器可能会有一定的性能开销
- 遍历过程中的修改限制:在遍历过程中修改集合可能会导致迭代器失效
- 复杂度增加:对于简单的集合,使用迭代器可能会增加不必要的复杂度
适用场景
- 需要统一遍历不同类型的集合时
- 需要隐藏集合内部实现细节时
- 需要支持多种遍历方式时
- 需要在遍历过程中添加额外操作时
实际应用
- Java集合框架中的Iterator接口
- Spring框架中的资源访问迭代器
- 数据库查询结果集的遍历
- 文件系统目录结构的遍历