
mybatis缓存架构
mybatis缓存分为一级缓存和二级缓存,一级缓存又叫做本地缓存。一级缓存默认开启,二级缓存默认关闭,二级缓存需要手动开启。
mybatis 缓存分为一级缓存和二级缓存如下图所示,一级缓存在单个会话上生效,二级缓存则可以在会话间共享。
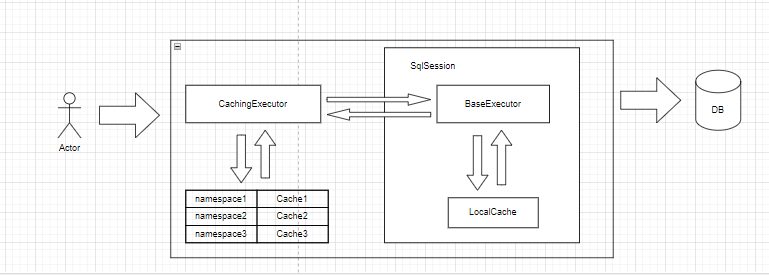
一级缓存
一级缓存也称为本地缓存,它是 MyBatis 默认开启的缓存机制。一级缓存的作用范围是
SqlSession,即同一个SqlSession范围内查询到的数据会被缓存起来,后续如果执行相同的查询语句,会直接从缓存中读取数据,而不会再次发送到数据库。
在BaseExecutor 类中,PerpetualCache localCache为一级缓存对象。在它的内部通过Map<Object, Object> cache = new HashMap<>()进行缓存的管理。key为CacheKey,value为数据库查询结果。
CacheKey
CacheKey 是用于生成缓存的 key。在BaseExecutor 中,CacheKey 通过方法 createCacheKey 创建,它包含以下信息:
- statementId:SQL 语句的唯一标识符。
- 分页参数:offset 和 limit。
- sql语句
- 查询参数
- 环境id,configuration中的环境配置
一级缓存源码
在BaseExecutor 类中,query 方法中,先创建CacheKey,通过cacheKey获取缓存,如果缓存中没有数据,则执行queryFromDatabase方法,查询数据库,并将查询结果放入缓存中。
try {
queryStack++;
// note zx 通过缓存key匹配数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
log.debug("一级缓存生效");
// note zx 该方法用于处理存储过程的输出参数
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
在queryFromDatabase方法中,先查询数据库,然后将查询结果放入缓存中。
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
log.debug("一级缓存保存查询结果" + key.toString());
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
上面的localCache为PerpetualCache,它位于BaseExecutor中,它是一个HashMap结构,key为CacheKey,value为数据库查询结果。
一级缓存的作用域
一级缓存存在两个作用域:SESSION 和 STATEMENT。
SESSION:缓存数据在当前会话中一直有效,直到会话结束。STATEMENT:缓存数据仅在当前 SQL 语句执行期间有效,当 SQL 语句执行完毕后,缓存数据将被清空。
默认情况下,一级缓存的作用域为 SESSION。
现在我们通过代码进行验证,代码如下。当设置缓存域为SESSION时,日志只打印了一次数据库查询日志。说明,我们的一级缓存生效了。
Author result;
// 设置session级别
SqlSession sqlSession1 = sqlSessionFactory.openSession();
Configuration configuration = sqlSession1.getConfiguration();
configuration.setLocalCacheScope(LocalCacheScope.SESSION);
log.debug("关闭 flushCache");
result = authorMapper.selectAuthorFlushCacheOff(999);
assertNotNull(result);
result = authorMapper.selectAuthorFlushCacheOff(999);
assertNotNull(result);
输出日志:
00:23:55.486 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 当前执行器类型为:SimpleExecutor
00:23:55.486 DEBUG [main] o.a.ibatis.session.LocalCacheTest - 关闭 flushCache
00:23:55.488 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - ==> Preparing: select * from author where id = ?
00:23:55.501 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - ==> Parameters: 999(Integer)
00:23:55.520 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - <== Total: 1
00:23:55.522 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 一级缓存生效
下面将缓存域设置为STATEMENT,日志打印了两次数据库查询日志。说明,我们的一级缓存失效了。
Author result;
// 设置statement级别
SqlSession sqlSession1 = sqlSessionFactory.openSession();
Configuration configuration = sqlSession1.getConfiguration();
configuration.setLocalCacheScope(LocalCacheScope.STATEMENT);
authorMapper = sqlSession1.getMapper(LocalCachedAuthorMapper.class);
log.debug("关闭 flushCache");
result = authorMapper.selectAuthorFlushCacheOff(999);
assertNotNull(result);
result = authorMapper.selectAuthorFlushCacheOff(999);
assertNotNull(result);
输出日志:
00:30:11.288 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 当前执行器类型为:SimpleExecutor
00:30:11.288 DEBUG [main] o.a.ibatis.session.LocalCacheTest - 关闭 flushCache
00:30:11.290 DEBUG [main] o.a.i.t.jdbc.JdbcTransaction - Opening JDBC Connection
00:30:11.292 DEBUG [main] o.a.i.t.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [org.apache.derby.impl.jdbc.EmbedConnection@396918327 (XID = 4946), (SESSIONID = 7), (DATABASE = ibderby), (DRDAID = null) ]
00:30:11.292 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - ==> Preparing: select * from author where id = ?
00:30:11.313 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - ==> Parameters: 999(Integer)
00:30:11.334 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - <== Total: 1
00:30:11.335 DEBUG [main] o.a.ibatis.executor.BaseExecutor - STATEMENT级别 清空一级缓存
00:30:11.338 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - ==> Preparing: select * from author where id = ?
00:30:11.338 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - ==> Parameters: 999(Integer)
00:30:11.339 DEBUG [main] o.a.i.b.L.selectAuthorFlushCacheOff - <== Total: 1
00:30:11.339 DEBUG [main] o.a.ibatis.executor.BaseExecutor - STATEMENT级别 清空一级缓存
另外需要说明的是,在MapperStatement中存在flushCache配置,如果该配置开启,则每次查询之前都会清理缓存。
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
然而,STATEMENT级别意味着关闭一级缓存吗?显然不是,它只是在当前SQL语句执行期间有效,对嵌套查询起作用。
举个例子:一个博客作者,通常会有多篇文章,当我们通过authorId查询文章,并嵌套查询作者信息。第一次需要从数据库中获取作者信息,之后的相同作者就会从缓存中获取。
下面通过代码进行验证,相关代码如下:
向数据库中插入作者信息及博客信息,其中博客id为1,3的是同一作者,authorId为101。
INSERT INTO author (id,username, password, email, bio, favourite_section) VALUES (101,'jim','********','jim@ibatis.apache.org','','NEWS');
INSERT INTO author (id,username, password, email, bio, favourite_section) VALUES (102,'sally','********','sally@ibatis.apache.org',null,'VIDEOS');
INSERT INTO blog (id,author_id,title) VALUES (1,101,'Jim Business');
INSERT INTO blog (id,author_id,title) VALUES (2,102,'Bally Slog');
-- note zx 嵌套查询缓存测试 1,3为同一作者
INSERT INTO blog (id,author_id,title) VALUES (3,101,'Good Food');
通过作者id查询博客信息,并嵌套查询作者信息。
<select id="selectBlogByAuthorId" parameterType="int" resultMap="blogWithPosts">
select * from Blog where author_id = #{authorId}
</select>
<resultMap id="blogWithPosts" type="Blog">
<id property="id" column="id"/>
<result property="title" column="title"/>
<association property="author" column="author_id" select="selectAuthor"/>
</resultMap>
<select id="selectAuthor" resultMap="selectAuthor">
select id, username, password, email, bio, favourite_section
from author where id = #{id}
</select>
最后我们将LocalCacheScope设置为STATEMENT,并关闭二级缓存,并执行查询。
<setting name="cacheEnabled" value="false"/>
<setting name="localCacheScope" value="STATEMENT"/>
下面是测试方法,这里我们查询博客信息后,对比两条博客中的作者对象是否相同,如果相同则使用的是缓存数据。
SqlSession sqlSession = sqlSessionFactory.openSession()
Configuration configuration = sqlSession.getConfiguration();
log.debug("useCache? " + configuration.isCacheEnabled());
log.debug("localCacheScope? " + configuration.getLocalCacheScope());
final BlogMapper blogMapper = sqlSession.getMapper(BlogMapper.class);
List<Blog> blogs = blogMapper.selectBlogByAuthorId(101);
assertNotNull(blogs);
Author author1 = blogs.get(0).getAuthor();
assertNotNull(author1);
Author author2 = blogs.get(1).getAuthor();
assertNotNull(author2);
assertSame(author1, author2);
输出日志:
10:49:20.667 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 当前执行器类型为:SimpleExecutor
10:49:20.673 DEBUG [main] o.a.i.s.n.NestedQueryCacheTest - useCache? false
10:49:20.673 DEBUG [main] o.a.i.s.n.NestedQueryCacheTest - localCacheScope? STATEMENT
10:49:20.695 DEBUG [main] o.a.ibatis.executor.BaseExecutor - ### queryStack: 1
10:49:20.719 DEBUG [main] o.a.i.s.n.B.selectBlogByAuthorId - ==> Preparing: select * from Blog where author_id = ?
10:49:20.779 DEBUG [main] o.a.i.s.n.B.selectBlogByAuthorId - ==> Parameters: 101(Integer)
10:49:20.822 DEBUG [main] o.a.ibatis.executor.BaseExecutor - ### queryStack: 2
10:49:20.822 DEBUG [main] o.a.i.s.n.AuthorMapper.selectAuthor - ====> Preparing: select id, username, password, email, bio, favourite_section from author where id = ?
10:49:20.834 DEBUG [main] o.a.i.s.n.AuthorMapper.selectAuthor - ====> Parameters: 101(Integer)
10:49:20.839 DEBUG [main] o.a.i.s.n.AuthorMapper.selectAuthor - <==== Total: 1
10:49:20.844 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 一级缓存保存查询结果-1992681480:2459226612:org.apache.ibatis.submitted.nested_query_cache.AuthorMapper.selectAuthor:0:2147483647:select id, username, password, email, bio, favourite_section
10:49:20.845 DEBUG [main] o.a.i.e.r.DefaultResultSetHandler - 嵌套查询使用缓存数据-1992681480:2459226612:org.apache.ibatis.submitted.nested_query_cache.AuthorMapper.selectAuthor:0:2147483647:select id, username, password, email, bio, favourite_section
10:49:20.848 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 一级缓存保存查询结果-361605327:70564671:org.apache.ibatis.submitted.nested_query_cache.BlogMapper.selectBlogByAuthorId:0:2147483647:select * from Blog where author_id = ?:101:development
10:49:20.848 DEBUG [main] o.a.ibatis.executor.BaseExecutor - STATEMENT级别 清空一级缓存
Preparing: select * from Blog where author_id = ?此处先查询数据库中的博客信息,紧接着嵌套查询作者信息,之后将作者信息放入本地缓存。
由于存在多条博客,第二个博客信息嵌套查询作者信息时,本地缓存存在数据,使用缓存数据。最后将博客查询数据缓存在本地,但由于我们的缓存域为STATEMENT,所以整个查询结束后,缓存数据被清空。
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// note zx MyBatis 利用本地缓存机制(Local Cache)防止循环引用和加速重复的嵌套查询。
// 默认值为 SESSION,会缓存一个会话中执行的所有查询。
// 若设置值为 STATEMENT,本地缓存将仅用于执行语句,对相同 SqlSession 的不同查询将不会进行缓存。
// issue #482
log.debug("STATEMENT级别 清空一级缓存 ");
clearLocalCache();
}
Info
当存在多个会话,操作同一个数据时,当一个会话将数据更新,其他会话中的缓存,由于不会清空,导致数据不一致问题。因此,我们通常将一级缓存级别设置为 STATEMENT。
一级缓存的清理
- 执行update相关操作,包括insert、update、delete
- flushCache设置为true
- sqlSession提交、回滚或者关闭
- localCacheScope设置为STATEMENT,并且查询结束(queryStack=0,嵌套查询存在缓存)。
关于flushCache
对于select类型的statement,默认flushCache=false。update、insert、delete类型的statement,默认flushCache=true。boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
一级缓存的触发条件
通过上面的介绍,总结下一级缓存的触发条件:
- 必须是同一个SqlSession
- 必须是同一个sql语句
- 必须是同一个statementId
- 查询参数相同
- 分页参数相同
- 环境id相同
- 没有提交、回滚或者关闭操作
二级缓存
在介绍二级缓存之前,我们需要了解下,mybatis中缓存的实现方式。
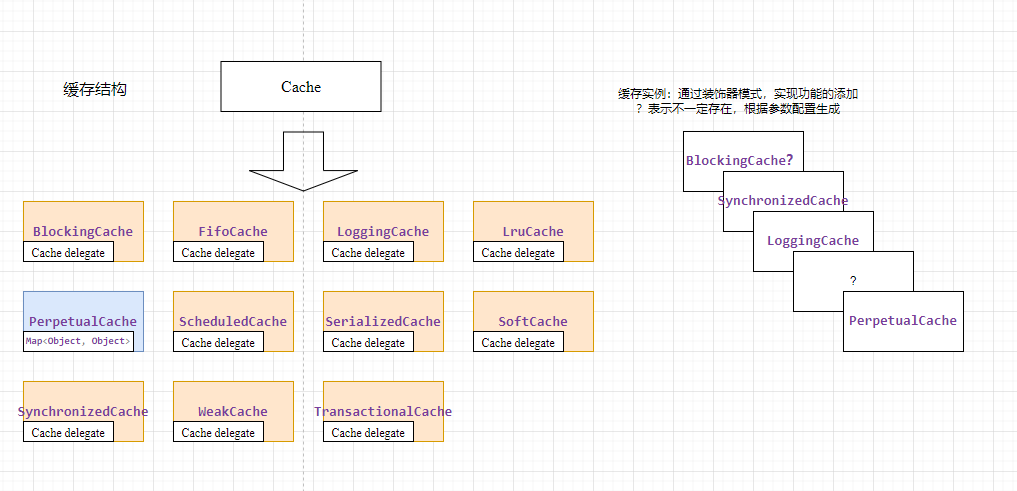
在mybatis中二级缓存使用装饰器进行实现,最底层的缓存类是PerpetualCache,它实现了Cache接口,并提供了缓存的基本操作。
其他的缓存类例如BlockingCache,SynchronizedCache,LoggingCache等,通过装饰器模式,对基础的缓存功能进行扩展。
二级缓存源码
在XmlMapperBuilder中,通过解析cache标签来创建缓存对象,并添加到configuration中。下面的方法是提取cache标签的参数配置。最后通过builderAssistant.useNewCache方法创建缓存对象。
private void cacheElement(XNode context) {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
我们主要看下useNewCache方法:
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
// note zx 创建缓存Cache实例
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
通过该方法创建cache实例,并添加到configuration中。configuration中维护了一个Map对象caches,key为namespace,value为Cache。
implementation这个方法是指定了缓存的默认实现类,我们可以自定义自己的缓存实现,需要在cache标签中指定type属性。addDecorator这个方法为缓存添加自动清理功能,存在4种清理策略:- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
其他方法都是对缓存属性的设置。并且对应不同的缓存实现类
在build中我们可以看到这些参数的实际作用,setStandardDecorators中设置的就是上图中的几个缓存类型。
public Cache build() {
// note zx 创建缓存Cache实例
setDefaultImplementations();
Cache cache = newBaseCacheInstance(implementation, id);
log.debug("== 默认缓存实例 " + implementation.getSimpleName());
setCacheProperties(cache);
// issue #352, do not apply decorators to custom caches
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
private Cache setStandardDecorators(Cache cache) {
// note zx 根据配置参数 装饰缓存。LoggingCache,和SynchronizedCache是默认装饰器
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
log.debug("== 添加缓存实例 ScheduledCache");
}
if (readWrite) {
cache = new SerializedCache(cache);
log.debug("== 添加缓存实例 SerializedCache");
}
cache = new LoggingCache(cache);
log.debug("== 添加缓存实例 LoggingCache");
cache = new SynchronizedCache(cache);
log.debug("== 添加缓存实例 SynchronizedCache");
if (blocking) {
cache = new BlockingCache(cache);
log.debug("== 添加缓存实例 BlockingCache");
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
缓存执行器 CachingExecutor
在配置xml中如果设置cacheEnabled为true,则会在创建执行器时,通过CachingExecutor进行装饰实际的执行器。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
// note zx 如果开启二级缓存,则创建CachingExcutor对象,装饰配置中的执行器
executor = new CachingExecutor(executor);
}
// note zx 插件 拦截 Executor
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
CachingExecutor中通过TransactionalCacheManager tcm管理事务缓存。当开启二级缓存后,通过tcm.getObject(cache, key);获取缓存记录,通过tcm.putObject(cache, key, list);记录缓存数据。
当缓存对象不存在时,直接通过委派执行器进行查询;缓存对象存在,首先判断当前sql是否需要清理缓存(如果时insert、update、delete操作,flushCache默认为true需要清理缓存,或者select指定flushCache为true),如果MapperStatement使用二级缓存,并且不存在resultHandler,则从二级缓存中获取数据,如果不存在缓存数据,则通过委派执行器查询数据,并将数据写入二级缓存中。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
// note zx statement 可以配置参数
// flushCache 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。
// useCache 将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true。
// 另外二级缓存的statement查询结果是指定resultHandler处理的,否则也不会开启二级缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
log.debug("cache key: " + key.toString());
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
} else {
log.debug("二级缓存生效");
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
二级缓存的命中与清理
二级缓存cacheKey的创建与一级缓存相同,除此之外二级缓存必须在提交之后才会真正写入,因此需要满足:
- 必须是同一个sql语句
- 必须是同一个statementId
- 查询参数相同
- 分页参数相同
- 环境id相同
- 执行提交操作后,再次查询
- useCache 为 true,cacheEnabled 为 true
- flushCache为false
通过代码进行验证,可以看到,两次对象查询结果相同。这里需要注意我们需要通过设置 <cache readOnly = "true" /> 关闭序列化和反序列化。
DefaultSqlSession sqlSession1 = (DefaultSqlSession) sqlSessionFactory.openSession();
UseCachedAuthorMapper authorMapper1 = sqlSession1.getMapper(UseCachedAuthorMapper.class);
DefaultSqlSession sqlSession2 = (DefaultSqlSession) sqlSessionFactory.openSession();
UseCachedAuthorMapper authorMapper2 = sqlSession2.getMapper(UseCachedAuthorMapper.class);
log.debug("================== flushCache 关闭 二级缓存验证");
Author result1 = authorMapper1.selectAuthorFlushCacheOff(999);
assertNotNull(result1);
sqlSession1.commit();
Author result2 = authorMapper2.selectAuthorFlushCacheOff(999);
assertNotNull(result2);
// 判断是否为缓存 如果通过相等进行判断需要关闭序列化和反序列化,
// 否则虽然走了缓存但是拿到的缓存对象是不同的,因为通过反序列化重新创建了对象
// 关闭方式为设置 readOnly = true
assertSame(result1, result2);
输出日志中可以看到已经命中了二级缓存,Cache Hit Ratio [org.apache.ibatis.builder.UseCachedAuthorMapper]: 0.5
09:47:12.932 DEBUG [main] o.a.ibatis.session.LocalCacheTest - ================== flushCache 关闭 二级缓存验证
09:47:12.985 DEBUG [main] o.a.ibatis.executor.CachingExecutor - cache key: -1710940381:1693866310:org.apache.ibatis.builder.UseCachedAuthorMapper.selectAuthorFlushCacheOff:0:2147483647:select * from author where id = ?:999:development
09:47:12.985 DEBUG [main] o.a.i.c.TransactionalCacheManager - 获取缓存 [class org.apache.ibatis.cache.decorators.SynchronizedCache]
09:47:12.985 DEBUG [main] o.a.i.c.d.TransactionalCache - 创建TransactionalCache: delegate is class org.apache.ibatis.cache.decorators.SynchronizedCache
09:47:12.985 DEBUG [main] o.a.i.builder.UseCachedAuthorMapper - Cache Hit Ratio [org.apache.ibatis.builder.UseCachedAuthorMapper]: 0.0
09:47:12.986 DEBUG [main] o.a.ibatis.executor.BaseExecutor - ### queryStack: 1
09:47:13.001 DEBUG [main] o.a.i.t.jdbc.JdbcTransaction - Opening JDBC Connection
09:47:13.002 DEBUG [main] o.a.i.t.jdbc.JdbcTransaction - Setting autocommit to false on JDBC Connection [org.apache.derby.impl.jdbc.EmbedConnection@2097614581 (XID = 26294), (SESSIONID = 7), (DATABASE = ibderby), (DRDAID = null) ]
09:47:13.003 DEBUG [main] o.a.i.b.U.selectAuthorFlushCacheOff - ==> Preparing: select * from author where id = ?
09:47:13.039 DEBUG [main] o.a.i.b.U.selectAuthorFlushCacheOff - ==> Parameters: 999(Integer)
09:47:13.215 DEBUG [main] o.a.i.b.U.selectAuthorFlushCacheOff - <== Total: 1
09:47:13.220 DEBUG [main] o.a.ibatis.executor.BaseExecutor - 一级缓存保存查询结果-1710940381:1693866310:org.apache.ibatis.builder.UseCachedAuthorMapper.selectAuthorFlushCacheOff:0:2147483647:select * from author where id = ?:999:development
09:47:13.221 DEBUG [main] o.a.i.c.TransactionalCacheManager - 获取缓存 [class org.apache.ibatis.cache.decorators.SynchronizedCache]
09:47:13.222 DEBUG [main] o.a.ibatis.executor.CachingExecutor - 二级缓存 保存数据-1710940381:1693866310:org.apache.ibatis.builder.UseCachedAuthorMapper.selectAuthorFlushCacheOff:0:2147483647:select * from author where id = ?:999:development
09:47:13.228 DEBUG [main] o.a.ibatis.executor.CachingExecutor - cache key: -1710940381:1693866310:org.apache.ibatis.builder.UseCachedAuthorMapper.selectAuthorFlushCacheOff:0:2147483647:select * from author where id = ?:999:development
09:47:13.228 DEBUG [main] o.a.i.c.TransactionalCacheManager - 获取缓存 [class org.apache.ibatis.cache.decorators.SynchronizedCache]
09:47:13.228 DEBUG [main] o.a.i.c.d.TransactionalCache - 创建TransactionalCache: delegate is class org.apache.ibatis.cache.decorators.SynchronizedCache
09:47:13.228 DEBUG [main] o.a.i.builder.UseCachedAuthorMapper - Cache Hit Ratio [org.apache.ibatis.builder.UseCachedAuthorMapper]: 0.5
09:47:13.228 DEBUG [main] o.a.ibatis.executor.CachingExecutor - 二级缓存生效-1710940381:1693866310:org.apache.ibatis.builder.UseCachedAuthorMapper.selectAuthorFlushCacheOff:0:2147483647:select * from author where id = ?:999:development
关于flushCache
flushCache为true时,会清空一级缓存、二级缓存。但是需要注意的是,如果没有进行提交操作,flushCache也不能真正清理掉二级缓存,它清理的只是事务缓存中的临时缓存。
查看事务缓存的相关代码,可以看到clear方法将临时缓存entriesToAddOnCommit设置为空,同时会设置clearOnCommit标记为true。当其为true时,通过getObject获取缓存,即使存在数据也会返回为空。
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
public Object getObject(Object key) {
// note zx 先从二级缓存中获取数据,如果未命中,则记录未命中的key
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}





