
look_look介绍
基于scrapy框架的爬虫项目,用于爬取常见网站的信息。
不要遮遮掩掩的,让我康康!
环境配置
创建conda环境
conda create -n look_look python=3.11.2
安装依赖
conda install --yes --file requirements.txt
目录结构
python包
config
自定义的系统配置,比如驱动,文件路径,redis key。
该包下的配置,可以在项目中直接引用,或者使用scrapy框架内的spider对象获取settings。
如果想让后者生效,需要在项目中的settings.py中引入对应的python文件,如下:from config.driver_config import * from config.web_config import * from config.path_config import *look_look/enhance
通常用于定义一些接口,或者爬虫通用的实现方法。look_look/spider
scrapy框架spider放到这个地方items.py
用于定义一些页面的字段middlewares.py
用于处理请求和响应pipelines.py
用于处理itemutils
工具方法
pipelines
| class | description |
|---|---|
| ExcelPipeline | 将item信息保存到excel,支持header自定义 |
| ImageSavePipeline | 图片链接保存 |
| MarkdownPipeline | 将html转换为markdown |
| MongoDBPipeline | 将item信息存储到mongo |
| RedisPipeline | 将链接存放到redis |
middlewares
| class | description |
|---|---|
| ChromeDownloaderMiddleware | 使用selenium获取动态网页内容 |
| RandomUserAgentMiddleware | 生成随机user-agent |
| CustomHeadersMiddleware | 添加自定义的header,同时还具有缓存header的功能,不过似乎没什么用e_e。 |
enhance
base_item
class description IItemSaveAction 提供保存item信息时需要提供的字段,下面的Action为具体化后的接口,配合指定的pipeline使用 RedisItemSaveAction 配合RedisPipeline使用 ExcelItemSaveAction 配合ExcelPipeline使用 MarkdownItemSaveAction 配合MarkdownPipeline使用 ImageItemSaveAction 配合ImageSavePipeline使用 base_spider
class method description BaseSpider get_run_config 加载运行配置:spider_config.RUN_SPIDER RedisCategorySpider get_category 存放redis时,指定key RedisCategorySpider get_key 存放redis时,生成key SeleniumSpider middleware_apply 使用selenium进行爬取 CustomHeaderSpider add 添加header,比如下载pixiv图片需要referer CustomHeaderSpider get_custom_headers 获取自定义的header BaseLoginSpider login 提供登录接口,所有的登录都要实现该接口 PixivLoginSpider login pixiv的登录实现 item_loaders
class description CleanItemLoader 自定义的itemloader,用于清理item字段的空格
其他
- logs 日志存放目录
- data 爬取的文件存放目录
如果缺少这两个目录需要创建。或者在
settings.py、以及上文说的config中另外指定
运行
运行项目只需要启动main.py即可。
过程与结果
以csdn文章爬取为例:
- 首先通过
CSDNSearchSpider查询相关主题的文章链接,并保存到redis中。 CSDNArticleSpider会监听redis中特定key下面是否有文章链接。有则进行文章的爬取。- 提取文章的标题、作者、点赞量、收藏量、阅读量等信息存储到excel中;并将文章的内容转换为markdown格式,保存到data目录中。
文章链接
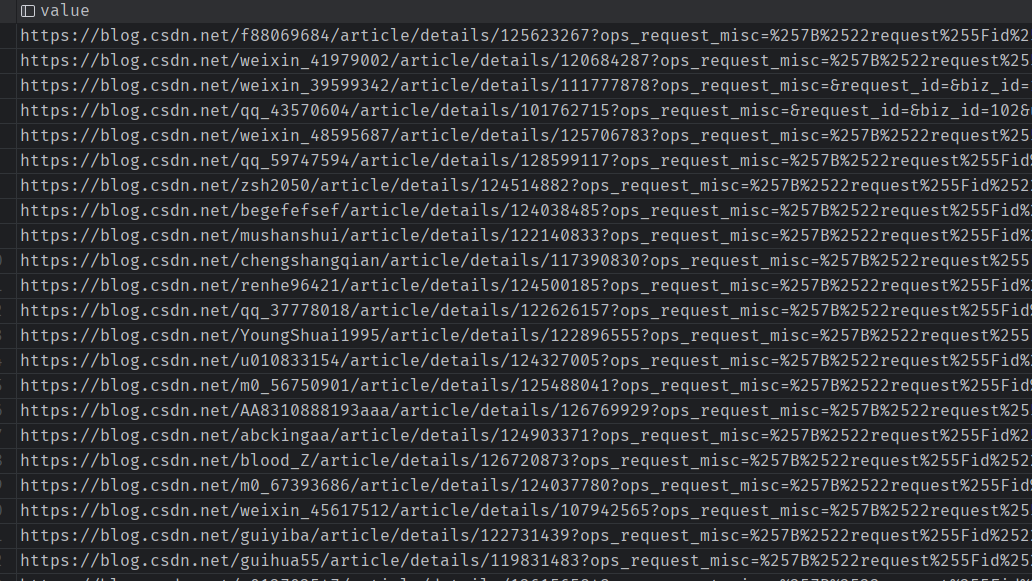
文章信息

文章内容
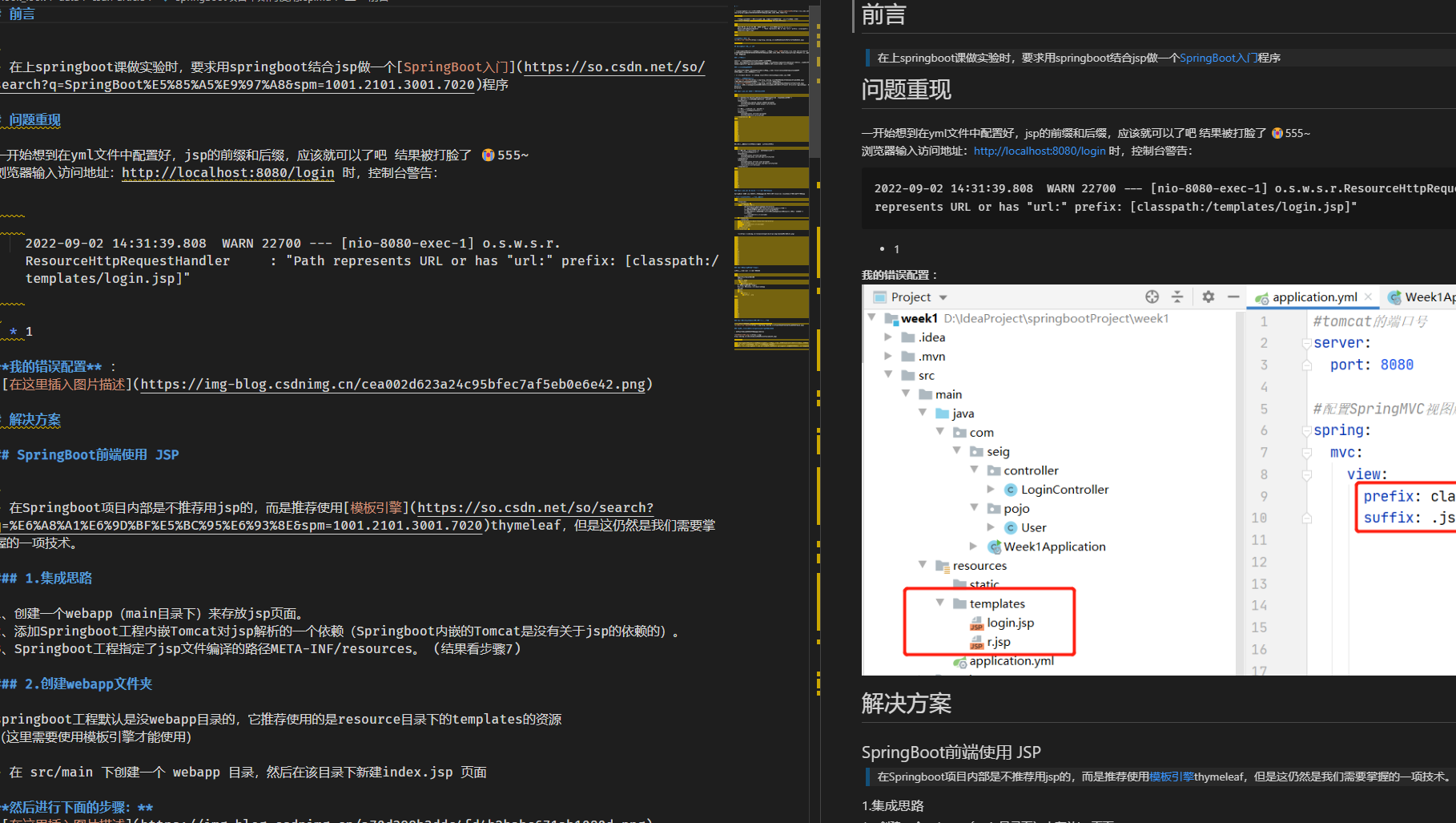
如何创建一个新的网站spider?
- 首先在spiders包下,新增该网站的爬虫的py文件,名字最好是该网站的名字
- 接下来你需要观察网页的构造。一般情况下,分为两个层次,最外层是一个列表,每一项会跳转到对应的详情页。
- 通常列表页,需要创建一个spider,用于爬取这些详情页的链接,爬取到的链接需要放到redis中。
- 之后再创建一个spider,用于爬取详情页数据。这里的spider需要是RedisSpider的子类。并且指定redis_key。
- 如果我们希望添加一些pipeline的能力,需要设置spider的custom_settings属性
- spider的parse方法中需要进行字段的提取,建议使用CleanItemLoader,它可以将字段首位的空格换行符号去除。
关于item的创建:
在第3步中,我们爬取链接并放到redis中,此时我们需要item具有提供url值的能力。只需要实现RedisItemSaveAction的get_category_field方法即可, 该方法需要返回字段名称,而不是字段值。
在base_item中还有其他的item父类,用于支持对应的pipeline能力。如:将item保存到mongo;导出item到excel;保存图片;保存网页为markdown等。
item一般放在items.py中,当然也可以创建新的文件存放。该项目之后都会放到spider中。(毕竟错误提交或者多提交了个人的spider相关的东西,被别人看到,不太好)
你可以参考项目中已经存在spider进行编程。
调试
执行main.py可以使用debug模式。但是使用命令行则不会触发debug。
如果程序报错,可以查看logs目录下的look_look.log文件中的报错信息。
支持的网站及功能
csdn
- [x] 查询页博客链接提取(存储到redis)
- [x] 根据博客链接爬取文章(保存excel,mongo,markdown)
效果
见上【过程与结果】
pixiv
- [x] 获取用户下的作品集
- [x] 作品及详情信息获取
- [x] 图片下载
效果展示
mongodb中存储信息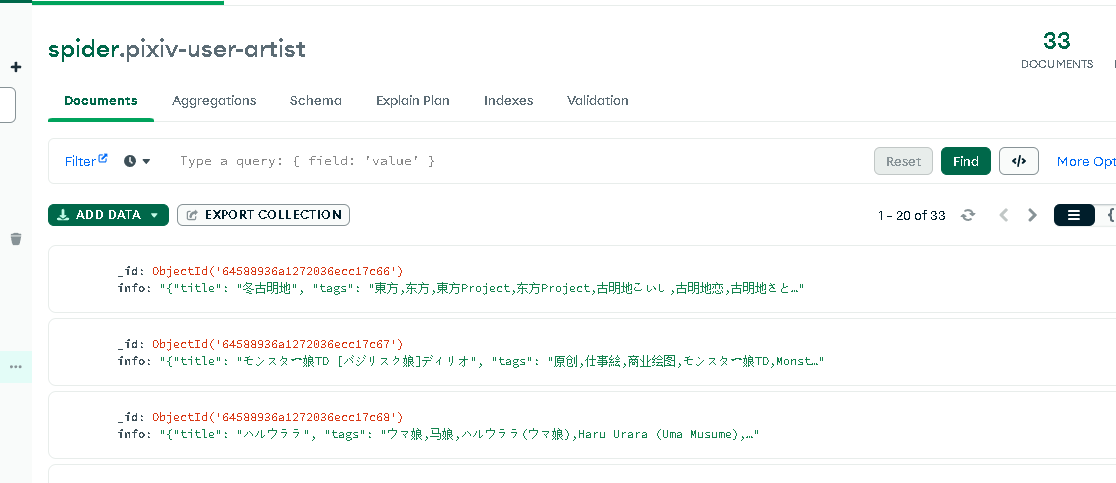 导出到excel中的信息
导出到excel中的信息 保存的图片
保存的图片
Q&A
- 如何指定启动哪些spider?
在main.py中我们通过代码的方式启动爬虫,因此可以设置你期望的爬虫类。 - 如何定制spider的middleware和pipeline?
这个属于scrapy的基本功能,可以在爬虫类中设置custom_settings属性。 - 动态网页如何爬取?
该项目中引入了selenium依赖,需要你在middleware中对请求和响应通过selenium进行处理。可以参考ChromeDownloaderMiddleware - 为什么redis中没有数据?
首先查看日志中是否有报错日志。如果没有,需要检查xpath是否正确。在页面上f12,通过$x即可测试。 - 为什么爬虫直接退出了,且没有报错?
如果是从redis拉取数据进行爬取,查看是否继承了RedisSpider或RedisCategorySpider。RedisSpider需要指定redis_key参数,RedisCategorySpider提供了一个从公共枚举和配置中获取该参数的方法,因此需要你指定枚举UrlType以及在配置文件(spider_config)中设置参数配置,该参数应该和之前的链接提取spider参数相同。 - 为什么浏览器一直白屏,后台不报错,似乎爬虫停住了?
检查下redis中是否有数据,否则爬虫会等待redis中有值后才会继续。